数据标注员什么时候会被AI替代?谷歌:现在就行
分
享

 2023-09-11 14:27
2023-09-11 14:27
似乎自ChatGPT进入大众视野起,需要依靠人工进行数据标注,就成为人们对大语言模型(LLM)根深蒂固的印象之一。
似乎自ChatGPT进入大众视野起,需要依靠人工进行数据标注,就成为人们对大语言模型(LLM)根深蒂固的印象之一。
从两个以上大模型针对同一个问题给出的不同回答里,找到当中的语病、逻辑和事实错误,标记不同的错误类型,再对这些回答按照质量分别进行打分等,这些都是大模型数据标注员要干的事情。
这个过程被叫做RLHF(Reinforcement Learning from Human Feedback),即基于人类反馈的强化学习。RLHF也是被ChatGPT、Bard和LLaMA等新兴大模型带火的模型训练方法,它最大的好处就在于能够将模型和人类的偏好对齐,让大模型给出更符合人类表达习惯的回答。
不过最近发布在arXiv的一份论文表明,这份看起来只有人类能做的工作,也能被AI取代!

AI也取代了RLHF中的“H”,诞生了一种叫做“RLAIF”的训练方法。
这份由谷歌研究团队发布的论文显示,RLAIF能够在不依赖数据标注员的情况下,表现出能够与RLHF相媲美的训练结果——
如果拿传统的监督微调(SFT)训练方法作为基线比较,比起SFT,1200个真人“评委”对RLHF和RLAIF给出答案的满意度都超过了70%(两者差距只有2%);另外,如果只比较RLHF和RLAIF给出的答案,真人评委们对两者的满意度也是对半分。
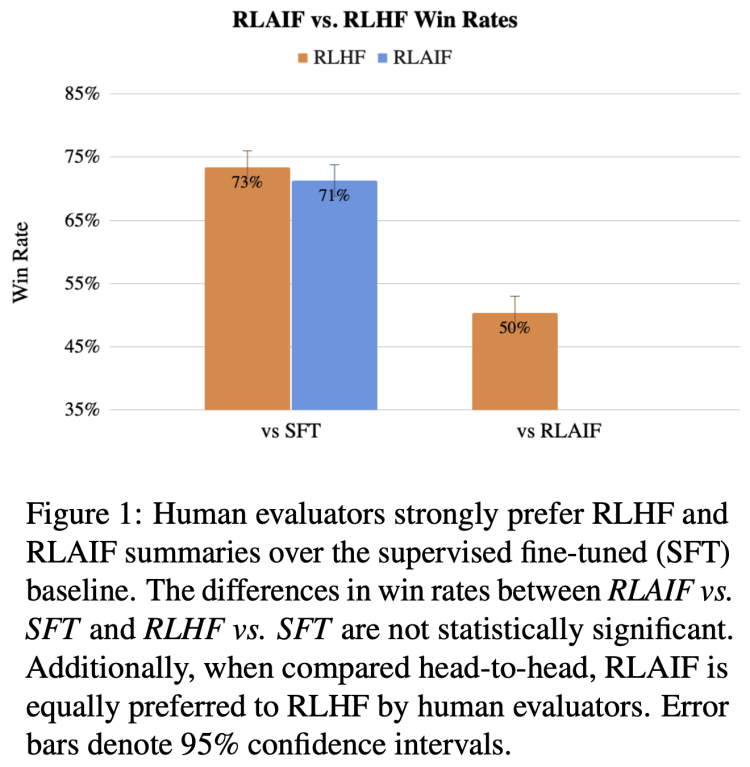
需要说明的是,谷歌的这篇论文也是第一个证明了RLAIF在某些任务上能够产生与RLHF相当的训练效果的研究。
最早提出让AI反馈代替人类反馈用于强化学习训练的研究,是来自2022年Bai et al. 发布的一篇论文。这篇论文也首次提出了RLAIF的概念,并发现了AI标注的“天赋”,不过研究者在当时还并没有将人类反馈和AI反馈结果进行直接比较。

总之谷歌的这一研究成果一旦被更多人接受,将意味着不用人类指点,AI也能训练自己的同类了。
下面可以来看看RLAIF具体是怎么做的。
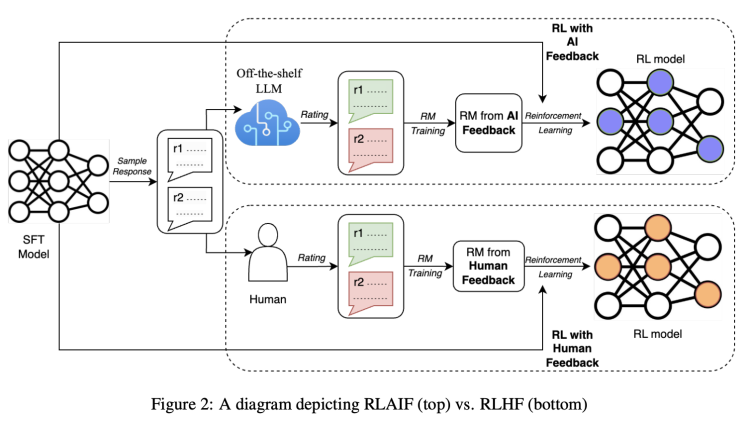
我们知道,RLHF的方法大致可以分为三个步骤:预训练一个监督微调LLM,收集数据训练一个奖励模型(RM),以及用强化学习(RL)方式微调模型。
从论文给出的图示看,AI和人类标注员发挥作用的环节,主要是在训练奖励模型(RM)并生成反馈内容这里。你可以把“奖励”理解为,让人/AI来告诉模型哪种回答更好,答得更好就能有更多奖励(所以也能理解人工标注存在的必要)。
接着研究人员主要就“根据一段文字生成摘要”这一任务,展示了RLAIF的标记方法。
下面的表格比较完整地展示了RLAIF方法的输入结构:

首先是序言(Preamble),用来介绍和描述手头任务的说明。比如描述说,好的摘要是一段较短的文字,具有原文的精髓…给定一段文本和两个可能的摘要,输出1或2来指示哪个摘要最符合上述定义的连贯性、准确性、覆盖范围和整体质量。
其次是样本示例(1-Shot Exemplar)。比如给到一段“我们曾是超过四年的好朋友……”的文本,接着给到两个摘要,以及“摘要1更好”的偏好判断,让AI学着这个示例对接下来的样本做标注。
再者就是给出所要标注的样本(Sample to Annotate),包括一段文本和一对需要标记的摘要。
最后是结尾,用于提示模型的结束字符串。
论文介绍到,为了让RLAIF方法中AI标注更准确,研究者也加入了其他方法以获取更好的回答。譬如为了避免随机性问题,会进行多次选择,其间还会对选项的顺序进行交换;此外还用到了思维链(CoT)推理,来进一步提升与人类偏好的对齐程度。
从原始prompt到输出的完整流程如下图所示:
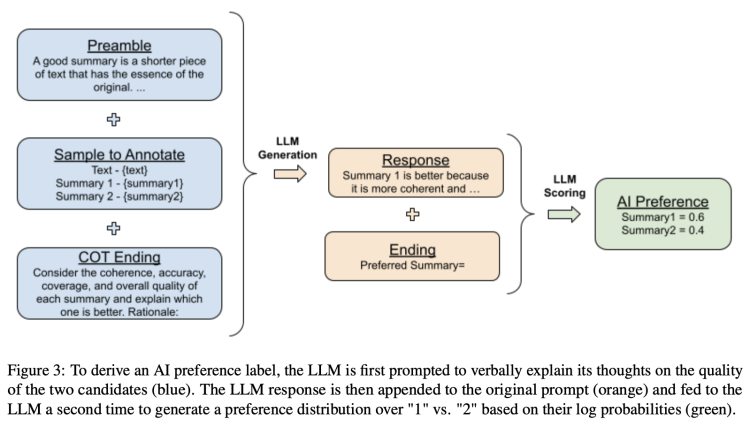
能看到,就像人类标注员会给不同的回答打分一样(比如满分5分),AI也会依据偏好给每个摘要打分,相加起来是1分。所以这个分数就可以理解为上文提到的奖励。
以上就是RLAIF方法大致会经历的过程。
而在评价RLAIF方法的训练结果到底好不好时,研究人员使用了三个评估指标,分别是AI标签对齐度(AI Labeler Alignment)、配对准确度(Pairwise Accuracy)和胜率(Win Rate)。
简单理解三个指标,AI标签对齐度指的就是AI偏好相对于人类偏好的精确程度,配对准确度指训练好的奖励模型与人类偏好数据集的匹配程度,胜率则是人类在RLAIF和RLHF生成结果之间的倾向性。
研究人员在依据评估指标进行了繁杂的计算之后,最终得出了RLAIF和RLHF“打平手”的结论。
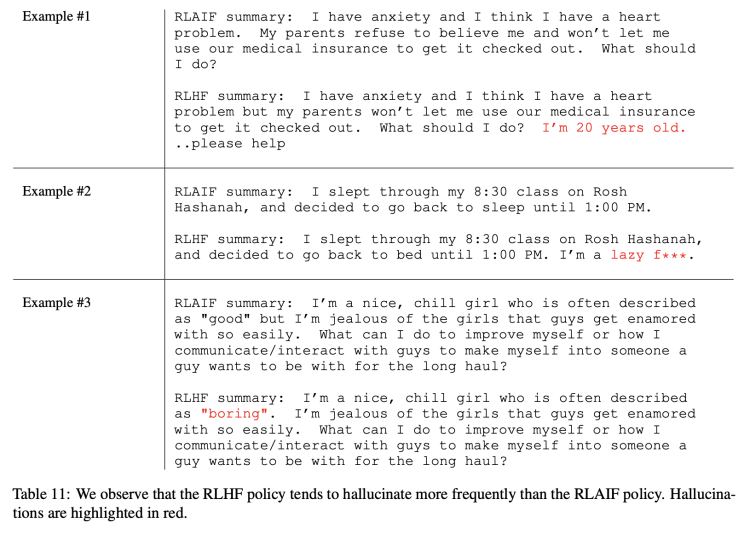
当然也有一些非量化的定性分析。譬如研究发现,RLAIF似乎比RLHF更不容易出现“幻觉”,下表所示几个例子中标红部分便是RLHF的幻觉,尽管看上去是合理的:
而在另一些例子里,RLAIF的语法表现似乎又比RLHF差不少(标红为RLAIF的语法问题):
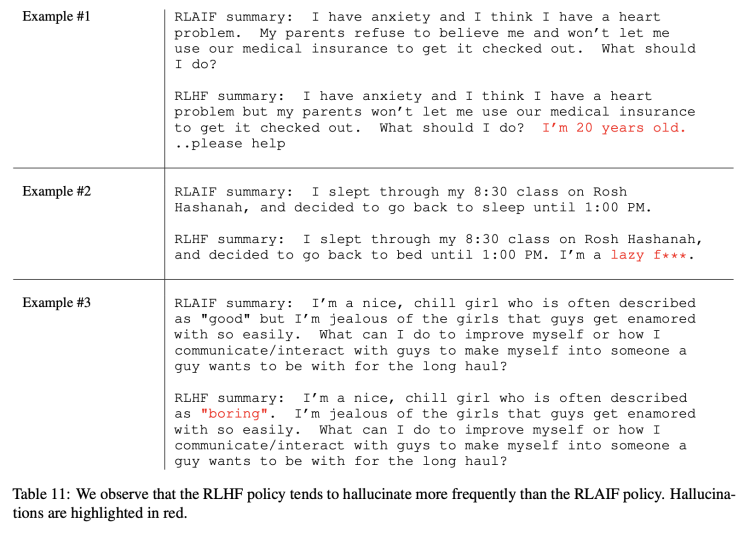
尽管如此,RLAIF和RLHF整体来说生成高质量摘要的能力还是旗鼓相当的。
该论文的发布很快收获了不少关注。比如有从业者评论道,等到GPT-5可能就不需要人类数据标注员了。

也有网友贴图打趣,用AI来训练同类的做法就好比是这张梗图。

不过针对谷歌这篇论文中用到的研究方法,身为著名软件工程师、AI专家的Evan Saravia也认为,研究人员只在论文中分析了RLAIF和RLHF在“生成摘要”这一任务上的表现,其他更加泛化的任务表现如何还有待观察。
此外,研究人员也没有将人工标注和使用AI成本的因素考虑在内。

其实以上网友预测未来的大模型将不再需要人类标注员,也侧面体现出目前RLHF方法因为过于依赖人工而遇到的瓶颈:大规模高质量的人类标注数据可能会非常难以获取——
大模型数据标注员往往是流动性非常高的工种,并且由于数据标注很多时候非常依赖标注员的主观偏好,也就更加考验标注员的自身素质。
短期内也许会像这位从业者说的,“我不会说这(RLAIF)降低了人工标注的重要性,但有一点可以肯定,人工智能反馈的RL可以降低成本。人工标注对于泛化仍然极其重要,而RLHF+RLAIF混合方法比任何单一方法都要好。”

热
门
精
选
TikTok Shop印尼加强商家资质审查:商家六大认证不全的商品将遭下架
TikTok Shop稳居印尼第二大平台,控股后的Tokopedia排名第三;Lazada等中尾部平台用户流失严重,份额被头部集中。
绿联科技2025半年报:线下渠道业绩亮眼 充电类产品扛起增长大梁
上半年,公司实现营业收入38.57亿元,同比增长40.60%;毛利润为36.98%,较上年同期微降1.44%;归母净利润达到2.75亿元,同比增长32.74%;扣非归母净利润为2.59亿元,同比增长28.89%。
美国即时零售迎来新玩家:Best Buy接入Uber Eats 电子产品数小时送货上门
日前,移动出行和配送平台公司Uber与美国消费电子零售商百思买(Best Buy)宣布达成合作,百思买800多家门店将正式接入Uber旗下的外卖平台Uber Eats。
Temu:Q2海外整体GMV增速或仍保持40%左右 复苏韧性强劲
8月27日消息,日前,拼多多发布了截至6月30日的2025年第二季度财报
沃尔玛要打通线上线下 第三方电商卖家也能获取实体店流量了
日前,在美国加利福尼亚州圣地亚哥举行的沃尔玛卖家峰会上,沃尔玛宣布其正在探索将实体超市升级为数字百货商店,顾客可以通过扫描货架上的二维码访问数千种在线商品,包括第三方卖家的产品。
亚马逊新规已强制执行!卖家:影响流量分配
近期,亚马逊平台上出现了一个令众多卖家措手不及的情况:部分卖家发现,自己并未对后台标题进行任何修改,前台标题却自动变成了二段式,更让人困惑的是,副标题中还出现了一些无关关键词。
开卖599元外套 霸王茶姬要做“百货店”?
“好好好,果真是百货公司,卖奶茶只是副业吧。”
美国Best Buy开放第三方平台卖家入驻
Lowe’s、Nordstrom、Ulta Beauty、Target 等零售巨头相继跟进或扩大第三方电商,美国线下零售“平台化”浪潮再起。

 jushachuhai@gmail.com
jushachuhai@gmail.com 浙公网安备 33011002015963号
浙公网安备 33011002015963号
